
CS 지식 질문
1. 웹 브라우저에 www.naver.com을 입력하면 일어나는 일 ⭐⭐⭐⭐⭐
답변 : 웹 브라우저 주소창에 URL 혹은 URI 를 입력하면(URL과 URI의 차이점 알아보기)
해당 호스트의 도메인 네임 IP 주소를 조회하기 위해서 먼저 PC의 1. DNS Cashe 를 확인하고 2. hosts 파일을 확인하여 해당 도메인 네임의 IP주소가 저장되어 있을 경우 그 주소를 가져오고 없을 경우 3. DNS 서버에서 4. IP 주소를 검색하여 가져오게 됩니다.
그리고 웹 브라우저가 찾은 IP주소를 기반으로 서버와의 5. TCP 연결을 시작하고 연결이 성공하면 6. HTTP Request 와 그에 따른 7. Response(컨텐츠)가 오게 됩니다.
8. 그리고 위의 모든 과정을 통해 해당 IP 주소의 웹 페이지에서 가져온 컨텐츠로 브라우저 렌더링을 통해 화면을 그려주게 됩니다.
DNS Cache
PC는 "www.naver.com" 의 IP주소를 성공적으로 받아왔었다.
몇 분 후 다시 "www.naver.com"에 방문하려고 했을 때, 또다시 위와 같은 복잡한 과정을 반복해서 IP 주소를 받아올까? 그러면 너무 비 효율적이다. 때문에, PC에는 DNS Cache라는 Cache를 활용해 Cache안에 자주쓴는 Domain Name 주소를 저장해 놓는다.
hosts 파일
hosts 파일은 IP 주소와 도메인 주소를 매핑해주는 파일이다.
보통, 주소창에 도메인으로 접속을 하면 DNS 서버를 통해 이에 대응하는 IP 주소를 찾아서 서버에 접속하게 된다. 이때 hosts 파일에 도메인과 IP를 임의로 지정하게 되면 DNS 서버보다 우선된다.
참고용 사이트
널널한 개발자 TV : 웹 브라우저에 URL 입력하면 일어나는 일 - 인프라 위주
https://www.youtube.com/watch?v=GAyZ_QgYYYo&t=341s
2. 프로세스와 스레드에 대해 설명하시오. ⭐⭐⭐⭐⭐
답변 : 프로세스는 자원을 할당받는 작업의 단위이며, 스레드는 프로세스가 할당받은 자원을 이용하는 실행의 단위. 스레드는 자원을 공유한다는 점이 차이점이 있습니다.
꼬리 질문 : 멀티 프로세스와 멀티 스레드의 차이점에 대해서도 설명해 주세요.
답변 : 멀티 프로세스와 멀티 스레드는 동시에 여러 작업을 수행하는 방법이지만, 그 방식에는 차이가 있습니다.
먼저 멀티 프로세스는 여러 개의 프로세스를 동시에 실행하는 방식을 말합니다. 멀티 프로세스의 각 프로세스가 독립적인 메모리 공간을 가지므로, 서로 간섭하지 않아서 한 프로세스의 오류가 다른 프로세스에 영향을 미치지 않습니다. 그러나 이러한 특성으로 자원 소모가 크고, 프로세스 간 통신이 복잡하다는 단점이 있습니다.
반면 멀티 스레드는 하나의 프로세스 내에서 여러 개의 스레드를 동시에 실행하는 방식으로 같은 프로세스 내에서 메모리를 공유하므로, 데이터 공유가 용이하지만 동기화 문제가 발생할 수 있으며, 한 스레드의 오류가 다른 스레드에 영향을 미칠 수 있습니다.
3. HTTP METHOD에 대해 설명해주세요.⭐⭐⭐
답변 : HTTP 메서드란 클라이언트와 서버 사이에 이루어지는 요청(Request)과 응답(Response) 데이터를 전송하는 방식을 일컫는다.
HTTP 메소드의 종류는 총 9가지가 있다. 이 중 주로 쓰이는 메소드는 5가지로 보면 된다.
주요 메소드
- GET : 리소스 조회
- POST : 요청 데이터 처리, 주로 등록에 사용
- PUT : 리소스를 대체(덮어쓰기), 해당 리소스가 없으면 생성
- PATCH : 리소스 부분 변경 (PUT이 전체 변경, PATCH는 일부 변경)
- DELETE : 리소스 삭제
기타 메소드
- HEAD : GET과 동일하지만 메시지 부분(body 부분)을 제외하고, 상태 줄과 헤더만 반환
- OPTIONS : 대상 리소스에 대한 통신 가능 옵션(메서드)을 설명(주로 CORS에서 사용)
- CONNECT : 대상 자원으로 식별되는 서버에 대한 터널을 설정
- TRACE : 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
출처: https://inpa.tistory.com/entry/WEB-🌐-HTTP-메서드-종류-통신-과정-💯-총정리 [Inpa Dev 👨💻:티스토리]
4. HTTP 상태 코드에 대해 말해주세요. ⭐⭐⭐
답변 : HTTP 상태 코드는 서버가 클라이언트의 요청을 처리한 결과를 나타내는 세 자리 숫자입니다. 이 코드는 클라이언트가 요청한 자원에 대한 처리 결과를 명확하게 전달해 줍니다. 상태 코드는 크게 다섯 가지 카테고리로 나눌 수 있습니다.
주요 상태 코드 (200, 404, 503)
- 200 : OK, 요청이 성공적으로 되었습니다. 정보는 요청에 따른 응답을 반환됩니다.
- 404: 서버는 요청받은 리소스를 찾을 수 없습니다. 브라우저에서는 알려지지 않은 URL을 의미합니다. APL에서 종점은 적절하지만 리소스 자체는 존재하지 않음을 의미할 수 있습니다. 서버들은 인증받지 않은 클라이언트로부터 리소스를 숨기기 위하여 이 응답을 403 대신에 전송할 수도 있습니다.
- 503 : 서버가 요청을 처리할 준비가 되지 않았습니다. 유지 보수를 위해 작동이 중단되거나 과부하가 걸린 서버일 경우 발생합니다.
- 1XX: Informational(정보 제공) : 임시 응답으로 현재 클라이언트의 요청까지는 처리되었으니 계속 진행하라는 의미입니다.
- 2XX: Success(성공) : 클라이언트의 요청이 서버에서 성공적으로 처리되었다는 의미입니다.
- 3XX: Redirection(리다이렉션) : 완전한 처리를 위해서 추가 동작이 필요한 경우입니다. 주로 서버의 주소 또는 요청한 URI의 웹 문서가 이동되었으니 그 주소로 다시 시도하라는 의미입니다.
- 4XX: Client Error(클라이언트 에러) : 없는 페이지를 요청하는 등 클라이언트의 요청 메시지 내용이 잘못된 경우를 의미합니다.
- 5XX: Server Error(서버 에러) : 서버 사정으로 메시지 처리에 문제가 발생한 경우입니다. 서버의 부하, DB 처리 과정 오류, 서버에서 익셉션이 발생하는 경우를 의미합니다.
5. GET과 POST의 차이는 무엇인가요? ⭐⭐⭐
답변 : GET은 주로 서버에서 데이터를 요청할 때 사용되며, 요청 데이터가 URL에 쿼리 문자열로 포함됩니다. 이로 인해 데이터가 노출되고, 전송할 수 있는 데이터 양에 제한이 있습니다. 또한, GET은 멱등성을 가지므로 동일한 요청을 여러 번 보내도 결과가 같고, GET 요청은 기본적으로 캐시될 수가 있어 같은 요청에 빠르게 응답할 수 있습니다.
답변 : POST는 데이터를 서버에 전송하거나 생성할 때 사용되며, 요청 본문에 데이터를 포함하기 때문에 더 많은 양의 데이터를 전송할 수 있고, URL에 노출되지 않아 보안성이 높습니다. POST는 멱등성이 없어서 같은 요청을 여러 번 보내면 데이터가 중복 생성될 수 있으며, POST 요청은 일반적으로 캐시되지 않습니다.
6. RESTful API 란? ⭐⭐⭐
답변 : RESTful API는 HTTP 프로토콜을 기반으로하는 웹 서비스 아키텍처입니다.자원, 메소드, 메시지 등을 정의하여 클라이언트 - 서버 간의 통신을 가능하게 합니다. 또한, RESTful API는 표준 HTTP 메소드(GET, POST, PUT, DELETE)를 사용하여 서버와 통신합니다.
우아한 테크 : [10분 테코톡] 정의 REST API
https://www.youtube.com/watch?v=Nxi8Ur89Akw
자바스크립트 면접 질문
7. Promise 의 개념에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변 : Promise는 비동기 작업의 결과를 나타내는 객체로, 비동기 처리가 진행 중이면 Pending, 성공이면 Fulfilled, 실패하면 Rejected라는 상태값을 가집니다.
Promise는 비동기 프로그래밍을 then 과 catch 의 체이닝을 통해 보다 간결하게 표현할 수 있도록 ES6에서 새로 도입되었습니다.
꼬리 및 연관 질문 : Promis 등장 이전에는 어떤 방식으로 비동기 처리를 했는지 설명해주세요(Callback)
답변 : Promise 등장 이전에는 비동기 작업을 처리하는 함수에 성공 콜백과 실패 콜백을 각각 넘겨서 완료 상태에 따른 처리를 했습니다. 이런 방식이다 보니, 두개 이상의 비동기 작업이 순서를 갖고 실행되어야 할 때, 콜백 함수 안에 또다른 콜백 함수가 점점 중첩되는 callback hell 현상이 발생하여 코드 가독성 및 유지보수성 저하의 요인이 된곤 했습니다.
꼬리 및 연관 질문 : async-await 에 대해 설명해주세요.
답변 : Promise의 완료를 기다리기 위한 문법으로 async 키워드로 정의한 함수 내에서 호출되는 Promise 앞에 await 키워드를 쓰면 해당 Promise 가 완료될 때까지 코드의 실행을 일시 중단할 수 있습니다. 이를 통해, 비동기 코드를 마치 동기 코드처럼 쉽게 작성할 수 있습니다.
꼬리 및 연관 질문 : async-await 를 사용할 때, 주의해야할 점을 알려주세요.
답변 : await 의 에러 핸들링은 반드시 try-catch 블록에서 해야합니다. 또한, await는 Promise가 완료될 때까지 함수의 실행을 중단하기 때문에 실행 흐름을 잘 고려하여 적재적소에 써야합니다. 예를 들어, 여러 비동기 작업이 순차적으로 진행될 필요가 없는 경우는 await 대신 Promise.all 함수를 사용하는 것이 바람직합니다.
8. var, let, const 차이를 설명해주세요. ⭐⭐⭐⭐⭐
var, let, const은 변수 선언 방식, 스코프, 그리고 호이스팅 이 3가지에서 가장 큰 차이점을 보인다고 생각합니다.
첫 번째로 변수 선언 방식입니다. var는 변수를 재선언하거나 재할당하는 것이 가능합니다. let은 변수 재선언은 불가능하지만 재할당은 허용됩니다. const는 변수를 선언하면서 동시에 초기화해야 하며, 재할당도 불가능합니다. 단, 객체 내부의 속성 변경은 가능합니다.
두 번째로 스코프 즉 유효한 참조 범위입니다. var는 함수 레벨 스코프를 가집니다. 따라서 함수 내부에서 선언된 변수는 해당 함수 내에서만 유효하며, 함수 외부에서는 참조할 수 없습니다. let과 const는 블록 레벨 스코프를 가집니다.
세 번째 호이스팅입니다. 우선 호이스팅이란 자바스크립트 함수는 실행되기 전 함수 내 필요한 변값들을 모두 모아 유효 범위의 최상단에 선언한 것처럼 동작하는 방식인데요. var로 선언된 변수는 호이스팅 시 변수의 선언만 최상단으로 끌어올려 지며, 초기화는 그대로 남아 있어 접근 시 undefined 값을 반환합니다. let과 const 역시 호이스팅되지만, '임시적 사각지대(TDZ)' 때문에 선언 이전에 변수에 접근하려고 하면 ReferenceError가 발생합니다.변수의 재할당이 필요 없거나 객체나 배열 내부의 값을 변경하는 것만 필요한 경우 const를 사용하는 것이 좋습니다. 반면, 변수의 재할당이 필요한 경우에는 let을 사용하는 것을 권장합니다.
9. 호이스팅(Hoisting) 이란? ⭐⭐⭐⭐⭐
답변 : 호이스팅이란, 변수와 함수의 선언문이 해당 스코프의 최상단으로 끌어올려지는 현상을 의미하며, 실제 코드의 위가 변경되는 것은 아니고 메모리 상에 먼저 올라가는 것을 뜻합니다.
이러한 현상으로 변수와 함수가 초기화 되기 전에 접근할 수 있는 현상이 발생합니다. 단, ES6에서 등장한 방식인 let 과 const 로 선언한 변수들은 호이스팅은 되지만, 초기화 전에 접근할 수는 없습니다.
꼬리 및 관련 질문 : 변수와 함수 모두 호이스팅이 동일하게 동작하나요?
답변 : 변수는 선언만 호이스팅 되지만, 함수는 선언과 초기화 모두 호이스팅 됩니다. 이러한 특성으로 인해, 변수는 초기화 전에 참조할 경우, undefined가 나오지만 함수는 초기화 전에 호출해도 정상적으로 호출이 가능합니다.
꼬리 및 관련 질문 : 왜 변수와 달리, 함수만 초기화 과정까지 호이스팅 되나요?
답변 : function 키워드로 선언한 함수는 선언과 초기화, 할당 단계가 내부적으로 동시에 진행되기 때문입니다. 반면 변수는 선언과 초기화를 한 구문으로 코딩했어도 내부적으로는 두 단계를 걸쳐서 실행됩니다.
꼬리 및 관련 질문 : 왜 let 과 const 으로 선언한 변수는 초기화 전에 접근할 수 없도록 막아 놓았나요?
답변 : 호이스팅 현상으로 인해, 초기화되지 않은 변수를 개발자가 참조할 수 없도록 하기 위해서 입니다. 즉 코드의 예측 가능성을 높이기 위해 Temporal Dead Zone(TDZ)이라는 개념을 도입한 것 입니다. 또한 자바스크립트의 창시자인 브랜든 아이크에 따르면 호이스팅 현상을 자바스크립트 개발 과정에서 실수로 생긴 일종의 버그이기 때문에, 이를 ES6 버전에서 해결한 것으로 보입니다.
꼬리 및 관련 질문 : 자바스크립트는 인터프리터 언어인데, 어떻게 호이스팅 현상이 일어날 수 있는건가요?
답변 : 일반적으로 알고 있는 인터프리터의 개념과는 달리 자바스크립트 엔진은 코드 실행을 위해 파싱과 실행이하는 두 단계를 거치게 됩니다. 호이스팅이 처리되는 파싱단계에서는 호이스팅 뿐만 아니라 구문 트리와 실행 컨텍스트를 생성하는 작업도 함께 수행됩니다.
참고용 사이트
프론트엔드 개발자 면접 단골 질문 8 | 자바스크립트 호이스팅
우아한 테크 : [10분 테코톡] 💙 하루의 실행 컨텍스트
10. 클로저(Closure)란? ⭐⭐⭐⭐⭐
답변 : 클로저는 함수와 그 함수가 선언됐을 때의 렉시컬 환경(Lexical environment)과의 조합이다.
클로저는 반환된 내부함수가 자신이 선언됐을 때의 환경(렉시컬 스코프)인 스코프를 기억하여 자신이 선언됐을 때의 환경(스코프) 밖에서 호출되어도 그 환경(스코프)에 접근할 수 있는 함수를 말한다.
즉, 클로저는 내부 함수가 외부 함수의 변수에 접근할 수 있도록 해주는 개념이다.
function outerFunc() {
// 외부 함수의 변수
var x = 10;
// 내부 함수에서 외부 함수의 변수에 접근할 수 있습니다.
var innerFunc = function () {
console.log(x);
};
return innerFunc;
}
var inner = outerFunc();
inner(); // 10위의 코드에서 outerFunc는 내부 함수 innerFunc를 반환하고 생을 마감했다.
즉, 실행 후 콜스택에서 제거가 되었기 때문에 생명 주기가 끝난 상태입니다.
따라서 outerFunc가 호출된 후에는 내부 변수 x도 유효하지 않을 것이라고 생각할 수 있지만 inner 함수를 호출하면 내부 함수 innerFunc가 실행되고, innerFunc는 선언된 당시의 환경을 기억하고 있기 때문에 (내 상위 스코프에는 var x가 선언 됐었지..) 변수 x의 값인 10이 출력된다.
이와 같이 생명 주기가 끝난 외부 함수의 변수에 접근할 수 있는 함수를 클로저라고 한다.
꼬리 및 연관 질문 : 클로저를 왜 사용하는 걸까요?
답변 :
1. 상태 유지: 클로저를 통해 함수의 상태를 유지할 수 있습니다. 예를 들어, 카운터 함수를 만들 때 클로저를 사용하여 카운터의 값을 유지하고 업데이트할 수 있습니다.
2. 데이터 은닉 : 클로저를 사용하면 외부에서 직접 접근할 수 없는 변수를 만들 수 있어, 데이터 은닉이 가능합니다. 이를 통해 모듈 패턴이나 정보 보호를 구현할 수 있습니다.
3. 전역변수 사용의 최소화 : 클로저를 사용하면 변수를 공유하는 특성은 유지하되 데이터를 은닉화할 수 있기 때문에, 전역 변수를 대체하여 안전한 코드를 작성할 수 있습니다.
꼬리 및 연관 질문 : 클로저를 사용할 때 주의할점
답변 : 클로저를 사용하면 메모리 측면에서 손해를 볼 수 있습니다. 클로저에 의해 내부 함수는 외부 함수의 변수를 참조하고 있어 외부 함수의 생명 주기가 끝났음에도 가비지 콜렉터에 의해 메모리가 해제되지 않습니다.
참고용 사이트
[10분 테코톡] 🍧 엘라의 Scope & Closure
https://www.youtube.com/watch?v=PVYjfrgZhtU
11. 실행컨텍스트란 무엇인가요? ⭐⭐⭐⭐⭐
답변 : 실행 컨텍스트는 코드가 실행될 때 생성되는 환경으로, 코드의 실행에 필요한 정보를 담고 있는 객체입니다. 해당 객체에는 변수 객체,스코프 체인, this 등의 정보가 담겨있습니다.
실행 컨텍스트는 코드가 실행될 때 생성되며 1. 전역 컨텍스트가 생성된 후 2. 함수 호출시마다 함수 컨텍스트가 생성되고, 3. 컨텍스트 생성이 완료된 후에 함수가 실행됩니다.
함수 실행 중에 사용 되는 변수들을 변수 객체 안에서 값을 찾고 값이 존재하지 않는다면 Lexical 환경의 outerEnvironmentReference를 통해 Scope 체인을 따라 올라가면서 탐색합니다. 함수 실행이 마무리가 되면 해당 컨텍스트는 사라지고, 페이지가 종료되면 전역 컨텍스트도 사라집니다.
참고용 사이트
우아한 테크 : [10분 테코톡] 💙 하루의 실행 컨텍스트
12. 불변성을 유지하려면 어떻게 해야하나요? ⭐⭐⭐⭐
답변 : 불변성(immutability)은 데이터가 생성된 후 변경되지 않도록 하는 특성을 의미합니다. 불변성을 유지하는 것은 여러 면에서 장점이 있으며, 특히 상태 관리와 관련된 애플리케이션에서 버그를 줄이고, 예측 가능한 동작을 보장하는 데 유용합니다.
불변성을 유지하기 위해서는 원시 값을 사용하거나, 객체를 복사하여 새로운 상태를 만들고, 불변성을 지원하는 라이브러리나 패턴을 활용함으로써 효과적으로 불변성을 관리할 수 있습니다.
ReactJS 면접 질문
13. Virtual DOM 무엇인지 설명해주세요. ⭐⭐⭐⭐⭐
답변 : Virtual DOM은 웹 성능을 최적화하기 위해 사용되는 DOM 관리 방법으로, 웹 어플리케이션의 상태 변경시, 객체 형태의 가상 DOM 을 통해 변경된 부분만 찾아내어 이를 실제 DOM에 적용하는 기능을 합니다.
Virtual DOM의 동작 순서는 Diffing 과 Reconiliation(리콘실레이션), 크게 두 가지로 구분할 수 있는데, Diffing 이란, Virtual DOM에서 변경점을 찾아내는 과정을 의미하며, Reconiliation이란, 찾아낸 변경점을 실제 DOM에 적용하는 과정을 의미합니다.
꼬리 및 연관 질문 : Virtual DOM이 동작하는 예시를 간략히 설명해주세요.
답변 : 먼저. 어플리케이션이 제일 처음 rendering 될 때, 어플리케이션의 초기 상태르르 담은 Virtual DOM을 메모리 상에 하나 생성합니다. 이후 어플리케이션이 실행되면서 state 나 props 가 변경된 부분이 있는 경우, 새로운 버전의 Virtual DOM 을 메모리 상에 하나 더 생성합니다.
새로운 버전의 Virtual DOM이 생성된 후 이전 버전의 Virtual DOM과 비교하는 과정인 Diffing에 돌입하고, 변경점을 찾아냅니다. 이 과정에서 두 Virtual DOM 트리의 각 노드를 비교하여 어떤 부분이 변경되었는지 확인합니다.
변경점을 찾아낸 이후에는, 실제 DOM에 적용하는 과정인 Reconiliation에 돌입합니다. 이 과정에서 변경된 부분만 실제 DOM에 업데이트하기 때문에, 브라우저 성능이 향상될 수 있는 것입니다.
Reconiliation이 완료된 이후에는 또 다른 변경점이 생기면, 구 버전의 Virtual DOM이 폐기되고 새로운 변경 사항을 반영한 최신 버전의 Virtual DOM이 다시 생성됩니다.
꼬리 및 연관 질문 : state나 props가 변경될 때마다 Diffing 과 Reconiliation 이 수행되는 건가요?
답변 : React를 비롯하여 Virtual DOM 을 사용하는 대부분의 프레임워크에서는 여러개의 상태 변화를 하나로 묶어 업데이트하는 Batch Update 를 지원하고 있습니다. 따라서, 짧은 시간 안에 여러 개의 state 와 props가 동시에 변경되면 이를 각각 처리하는 것이 아니라, 한꺼번에 모아서 처리합니다.
꼬리 및 연관 질문 : Virtual DOM을 사용하는 것이 그렇지 않은 것보다 좋은가요?
답변 : 항상 그런 것은 아닙니다, 간단한 어플리케이션의 경우에는 Virtual DOM 을 사용하는 것이 오히려 오버헤드를 초래할 수 있습니다. 왜냐하면 Virtual DOM 자체도 메모리 공간을 차지하고 Diffing 하는 과정 역시, CPU를 활용하기 때문입니다.
다만, DOM 트리가 복잡하고, 상태 변경도 빈번하게 일어나는 대규모 어플리케이션에서 사람의 인지 능력으로는 정확히 어떤 DOM을 업데이트해야 하는지 식별하기 어렵기 때문에 Virtual DOM 을 사용하는 것입니다.
꼬리 및 연관 질문 : Virtual DOM 과 리얼 돔의 차이를 설명해주세요.
답변 : 리얼 돔은 돔 요소를 조작하는 반면에, 가상 돔은 돔 요소를 객체 형태로 메모리에 저장하기 때문에 실제 돔을 조작하는 것보다 훨씬 빠르게 조작을 수행할 수 있습니다.
즉, 실제 돔을 조작하는 것보다 메모리상에 올라와 있는 자바스크립트 객체를 변경하는 작업이 훨씬 더 가벼우므로 가상돔을 사용합니다. 그래서 리액트는 가상 돔을 이용해서 리얼 돔을 변경하는 작업을 상당히 효율적으로 수행합니다.
14. React를 사용하는 이유에 대해 말씀해주세요. ⭐⭐⭐⭐
답변 : React는 현대 웹 애플리케이션 개발에 널리 사용되는 JavaScript 라이브러리로, 컴포넌트 기반 아키텍처를 통해 UI를 독립적인 컴포넌트로 나누어 재사용성과 유지보수를 용이하게 합니다.
가상 DOM을 활용하여 실제 DOM과의 차이를 계산하고 필요한 부분만 업데이트함으로써 성능을 향상시킵니다. 데이터 흐름은 단방향으로 유지되어 디버깅과 상태 관리가 간편하며, Hooks 기능을 통해 함수형 컴포넌트에서도 상태와 생명주기를 관리할 수 있습니다.
또한, 서버 사이드 렌더링(SSR)을 지원하여 초기 페이지 로드 성능과 SEO에 유리합니다.
15. 리액트에서 JSX 문법이 어떻게 사용되나요? ⭐⭐⭐
답변 :
JSX는 JavaScript와 XML이 결합된 문법으로, React에서 UI를 정의하는 데 사용됩니다.
JSX에서는 컴포넌트가 반드시 하나의 부모 요소로 감싸져야 하며, 이는 Virtual DOM의 효율적인 비교를 위한 규칙입니다.
속성을 전달할 때는 중괄호 {}를 사용하여 JavaScript 표현식을 삽입하고, 문자열 속성은 따옴표로 감쌉니다.
조건부 연산을 위해 if문 대신 삼항 연산자를 사용하며, 스타일을 적용할 때는 객체 형태로 작성하고 카멜 표기법을 사용해야 합니다. 또한, HTML에서 사용하는 class 대신 className을 사용합니다.
16. 라이프사이클이 의미하는 바에 대해서 설명해 보세요. ⭐⭐⭐⭐⭐
답변 :
라이프사이클은 일반적으로 어떤 객체나 시스템이 생성되어 사용되고 종료되는 일련의 전체 과정을 말합니다. 컴포넌트는 일반적으로 생성, 마운트, 업데이트, 언마운트의 라이프사이클을 거칩니다.
생성 단계는 컴포넌트가 메모리에 생성되는 단계입니다. 초기 상태와 props가 설정됩니다. 마운트 단계에서는 컴포넌트가 화면에 처음으로 그려집니다. 업데이트 단계에서는 컴포넌트의 상태나 속성이 변경되어 화면에 그려집니다. 언마운트 단계에서는 컴포넌트가 화면에서 사라지는 단계를 말합니다.
라이프사이클은 컴포넌트가 동작하고 작업을 수행하는 과정을 이해하는 것에 꼭 필요한 개념입니다. 외부 데이터를 가져오는 작업은 마운트 단계에서 수행하는 것이, 불필요한 리소스를 정리하는 것은 언마운트 단계에서 수행하는 것이 적절하다는 것을 판단하는 것에 필요합니다.
17. React Hooks에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변 : React Hooks는 함수형 컴포넌트에서 상태(state)와 생명주기(lifecycle) 기능을 사용할 수 있도록 해주는 특별한 함수입니다. React 16.8에서 도입된 Hooks는 클래스형 컴포넌트 없이도 상태 관리와 사이드 이펙트를 처리할 수 있게 해주어, 코드의 재사용성과 가독성을 향상시킵니다.
주요 Hooks
1. useState : 컴포넌트의 상태를 관리하기 위해 사용됩니다.
2. useEffect : 사이드 이펙트를 처리하기 위해 사용됩니다. API 호출, 구독 설정, 타이머 등 다양한 비동기 작업을 수행할 수 있습니다.
3. useContext : Context API와 함께 사용되어, 컴포넌트 트리에서 데이터를 쉽게 공유할 수 있도록 해줍니다.
4. useReducer : 복잡한 상태 관리를 위해 사용됩니다. Redux와 유사한 방식으로 상태를 업데이트할 수 있습니다. 상태와 디스패치 함수를 반환하며, 액션에 따라 새로운 상태를 반환하는 리듀서를 정의합니다.
5.useRef : DOM 요소에 직접 접근하거나, 컴포넌트의 렌더링 간에 값을 유지할 때 사용됩니다.
변경해도 리렌더링되지 않기 때문에, 이전 값을 저장하는 데 유용합니다.
18. useEffect의 실행 순서에 대해 설명해 보세요. ⭐⭐⭐⭐
답변 :
첫 번째로, 컴포넌트가 렌더링되면 useEffect의 내용이 실행되기 전의 화면이 제일 먼저 그려집니다.
두 번째, useEffect 내의 콜백 함수가 실행됩니다.
세 번째, useEffect의 두 번째 매개변수로 전달된 의존성 배열 체크가 진행됩니다.
네 번째, 만약 의존성 배열에 들어있는 값이 변경되면 컴포넌트 re-rendering이 진행되고 useEffect의 내용이 다시 실행됩니다.
컴포넌트가 마운트될 때 setup 함수가 호출되고, 그 뒤 컴포넌트의 상태나 속성이 변경될 때 실행되어 변경 이전 값으로 clean up 함수가 호출되고 변경 이후 값으로 setup 함수가 호출된다고 말할 수 있습니다.
19. useEffect와 useLayoutEffect의 차이점에 대해 설명해주세요. ⭐⭐⭐⭐
답변 :
제일 큰 차이점은 useEffect는 비동기적으로 동작하고, useLayoutEffect는 동기적으로 동작한다는 것입니다. 리액트에서 useEffect는 렌더링이 끝나고 특정 행동을 수행하고, useLayoutEffect는 렌더링 전에 특정 행동을 수행합니다.
따라서 성능 모니터링이나 애니메이션 구현 등 즉시 반응이 필요한 경우에 useLayoutEffect를 사용하고, 네트워크 요청, DOM 접근, 비동기 작업을 하는 경우에는 useEffect를 사용하는 것이 좋습니다.
20. Key Props를 사용하는 이유에 대해 설명해주세요. ⭐⭐⭐⭐
답변 :
React에서 key props는 리스트를 렌더링할 때 각 요소를 고유하게 식별하기 위해 사용됩니다.
key는 React의 가상 DOM이 어떤 요소가 변경되었는지를 효율적으로 결정하는 데 중요한 역할을 합니다.
21. 왜 state를 직접 변경하지 않고, useState를 사용해야 하나요? ⭐⭐⭐⭐⭐
답변 :
useState를 사용하면 상태가 변경될 때 React가 자동으로 컴포넌트를 리렌더링합니다.
상태를 직접 변경할 경우 (state.value = newValue) React는 해당 변경 사항을 감지하지 못하기 때문에 리렌더링이 발생하지 않습니다.
React는 상태 변경을 감지하기 위해 참조(Reference) 비교를 사용합니다. useState의 상태 업데이트 함수 (setState)는 새로운 상태 객체를 반환하여 상태가 변경되었음을 React에 알립니다. 직접 상태를 변경하면 객체의 참조가 동일하게 유지되므로 React는 변경을 감지하지 못합니다.
React의 상태 업데이트 배치 처리 setState는 비동기적으로 동작하며, 여러 상태 업데이트를 배치(batch)로 처리하여 성능을 최적화합니다. 직접 상태를 변경하면 이러한 최적화가 이루어지지 않습니다.
꼬리 및 연관 질문 : 상태 관리를 왜 할까요? 그리고 평소 state 관리는 어떻게 하시나요?
답변 :
리액트에서는 상태(state)가 변화하면 렌더링이 일어납니다.
서로 다른 두 컴포넌트에 같은 데이터가 필요할 때, 각 컴포넌트 간 부모-자식 관계가 아닌 이상 직접적인 데이터 전달이 어렵고, 상태가 많아지고 복잡해질수록 props 추적이 어려워집니다.(props drilling 현상).
그래서 간단한 작업은 useState 같은 리액트 훅을 사용하여 컴포넌트의 상태를 관리하고, 규모가 큰 컴포넌트 상태 관리는 state를 전역변수처럼 만들어 모든 컴포넌트에 상태를 전달해주지 않고도 어떤 컴포넌트에서든 바로 state에 접근할 수 있게 해주는 redux 와 같은 상태 관리 라이브러리를 사용할 수 있습니다.
22. Props에 대해 설명해주세요. ⭐⭐⭐
답변 :
props는 컴포넌트에 전달해주는 값으로, 매개변수와 같은 역할을 합니다.
props는 부모 컴포넌트와 자식 컴포넌트를 독립적으로 생각할 수 있도록 도와줍니다.
꼬리 및 연관 질문 : Prop Drilling에 대해 설명해주세요.
답변 : props를 UI 트리 깊숙이 전달해야 하거나 여러 컴포넌트에 동일한 props가 필요한 경우, props 전달이 굉장히 불편해 집니다. 이렇게 props를 계속 이어서 전달하는 상황을 prop drilling이라고 부릅니다.
꼬리 및 연관 질문 : Props와 State의 차이에 대해 설명해주세요.
답변 : props는 함수 매개변수처럼 컴포넌트에 전달되는 반면 state는 함수 내에 선언된 변수처럼 컴포넌트 안에서 관리됩니다.
23. 리액트에서 메모이제이션을 어떤 방식으로 하나요? ⭐⭐⭐⭐⭐
답변 :
메모이제이션은 컴퓨터가 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로서 동일한 계싼을 하지 않도록 하여, 속도를 높이는 기술이다. 보통 애플리케이션의 최적화를 위해 사용된다.
리액트에서 메모이제이션을 하는 방식은 주로 두 가지 훅인 useMemo와 useCallback을 통해 이루어집니다
useMemo는 계산 비용이 큰 값을 메모이제이션하여, 의존성이 변경되지 않는 한 이전에 계산한 값을 재사용합니다. 주로 복잡한 계산을 수행할 때 사용되며, 렌더링 성능을 향상시킵니다.
useCallback은 함수를 메모이제이션하여, 동일한 의존성 배열을 가지고 있는 한 같은 함수를 재사용합니다. 주로 자식 컴포넌트에 함수를 props로 전달할 때 불필요한 렌더링을 방지하는 데 사용됩니다.
React.memo는 고차 컴포넌트(Higher-Order Component)로, 컴포넌트의 props가 변경되지 않는 한 리렌더링을 방지합니다. 이와 함께 useCallback을 사용하면, props로 전달된 함수가 변경되지 않을 때 자식 컴포넌트의 리렌더링을 방지할 수 있습니다.
24. useMemo와 useCallback에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변 :
1. useCallback: 함수를 메모이제이션하여, 동일한 의존성 배열을 가지고 있는 한 같은 함수를 재사용합니다. 주로 자식 컴포넌트에 props로 함수를 전달할 때 불필요한 렌더링을 방지하기 위해 사용됩니다.
- a나 b가 변경될 때만 새로운 함수 생성.
const memoizedCallback = useCallback(() => {
doSomething(a, b);
}, [a, b]);2. useMemo: 계산 비용이 큰 값을 메모이제이션하여, 의존성이 변경되지 않는 한 이전에 계산한 값을 재사용합니다. 주로 성능 최적화를 위해 사용됩니다.
computeExpensiveValue는 a나 b가 변경될 때만 호출.
memoizedValue는 의존성이 변경되지 않으면 캐시된 값을 반환.
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);차이점 요약
| useMemo | useCallback |
| 값(결과)을 메모이제이션 | 함수 자체를 메모이제이션 |
| 연산 비용이 높은 계산을 최적화 | 동일한 함수 참조를 유지하여 불필요한 재생성 방지 |
| useMemo(() => computeValue, [deps]) | useCallback(() => doSomething, [deps]) |
사용 예시
- useMemo: 복잡한 계산 결과를 재사용해야 할 때.
- useCallback: 함수가 자식 컴포넌트의 props로 전달되어, 불필요한 리렌더링을 방지할 때.
Redux/Recoil/상태관리
25. 상태관리 라이브러리를 사용하는 이유가 무엇인가요? ⭐⭐⭐⭐
1. 전역 상태 관리
- 애플리케이션 전반에서 공유되어야 하는 상태를 효율적으로 관리할 수 있습니다.
- 상태를 여러 컴포넌트로 쉽게 전달하거나 공유할 수 있어, Prop Drilling(깊은 Prop 전달) 문제를 해결합니다.
2. 일관된 상태 관리
- 상태 관리 라이브러리는 상태의 변경 방식과 흐름을 명확히 정의하여, 예측 가능하고 일관된 방식으로 상태를 변경할 수 있도록 돕습니다.
3. 디버깅 및 상태 추적
- 대부분의 상태 관리 라이브러리는 디버깅 도구(예: Redux DevTools)를 지원하여 상태 변화의 히스토리를 쉽게 추적할 수 있습니다.
- 상태 변경, 액션 디스패치, 현재 상태 등을 시각적으로 확인할 수 있어 버그 해결이 용이합니다.
4. 복잡한 상태 로직 관리
- 비동기 작업(예: API 호출, 데이터 페칭)을 포함한 복잡한 상태 로직을 깔끔하게 처리할 수 있도록 도와줍니다.
- 미들웨어 또는 내장 기능을 통해 비동기 로직을 단순화할 수 있습니다.
5. 유지보수성 향상
- 상태와 상태 변경 로직이 분리되어 코드가 모듈화되고 구조화됩니다.
- 상태 관리가 체계적으로 이루어져, 대규모 애플리케이션에서도 확장성과 유지보수성이 향상됩니다.
6. 컴포넌트 리렌더링 최적화
- 상태 관리 라이브러리는 특정 상태에 의존하는 컴포넌트만 리렌더링하여 성능 최적화를 지원합니다.
- 불필요한 리렌더링을 줄여 UI 성능을 개선할 수 있습니다.
26. Redux를 사용하는 이유가 무엇인가요? ⭐⭐⭐⭐
답변 :
리덕스는 전역 상태 관리 라이브러리로서 쉽게 말해 "중앙 state 관리소" 역할을 하는 라이브러리입니다.
리덕스를 사용하는 이유는 크게 2가지가 있다고 생각합니다.
먼저, ‘useState의 불편함' 입니다.예를 들어 A라는 컴포넌트에서 C라는 컴포넌트로 state 값을 전달해주기 위해서는 반드시 부모-자식 관계가 되어야 하는데 만약 그 사이에 B 컴포넌트가 있다면 B 컴포넌트에선 그 state를 사용하지 않더라도 무조건 받아서 C 컴포넌트로 props를 내려줘야 하는 불편함이 있습니다.
두번째는 'Global state의 편리함' 입니다. 중앙 state 관리소에서 생성된 state들을 의미하는데 이 state들을 필요로 하는 컴포넌트가 어디에 위치하고 있든 간에 상관없이 state 불러올 수 있다는 장점이 있습니다.
꼬리 및 연관 질문 : Redux말고 다른 전역 상태 관리에 대해 아는 것 하나와 차이점을 말해주세요.
답변 :
Zustand는 React 애플리케이션을 위한 간단하고 가벼운 상태 관리 라이브러리로
Redux는 액션, 리듀서, 스토어 등의 보일러플레이트 코드가 필요하지만, Zustand는 이러한 설정이 거의 필요 없습니다. 상태를 정의하고 사용하는 것이 매우 간단합니다.
Redux는 중앙 집중식 상태 관리를 지향하지만, Zustand는 더 유연하게 여러 스토어를 조합하여 사용할 수 있으며 Redux는 상태가 변경되면 관련된 모든 컴포넌트를 리렌더링할 수 있지만, Zustand는 상태를 구독한 컴포넌트만 리렌더링하게 되어 성능 면에서 유리할 수 있습니다.
Zustand는 간편한 사용성과 유연성 덕분에 작은 프로젝트부터 중규모 애플리케이션까지 폭넓게 활용될 수 있는 상태 관리 라이브러리입니다.
27. Context API와 Redux를 비교해주세요. ⭐⭐⭐⭐⭐
답변 :
Context API 는 전역 상태를 간단하게 관리하고 여러 컴포넌트 간에 데이터를 공유할 수 있도록 돕습니다. 설정이 간단하고, createContext와 Provider를 사용하여 쉽게 구현할 수 있습니다. 상태를 직접 관리하며, Provider 아래의 모든 소비자 컴포넌트가 리렌더링됩니다. 상태 변경 시 모든 하위 컴포넌트가 리렌더링될 수 있어 성능 문제가 발생할 수 있습니다.
Redux 는 상태 관리 라이브러리로, 복잡한 애플리케이션의 상태를 중앙 집중식으로 관리하여 일관성과 예측 가능성을 제공합니다. 초기 설정이 복잡하고 보일러플레이트 코드가 많으며, 액션과 리듀서를 사용하여 상태를 관리합다. createStore를 통해 스토어를 만들고, Provider로 애플리케이션을 감싸서 상태를 제공합니다.
상태는 중앙 스토어에 저장되고, 상태 변경은 액션을 통해 이루어져 필요한 컴포넌트만 리렌더링됩니다. 필요한 컴포넌트만 리렌더링되므로 성능이 더 최적화됩니다.
28. React Query 란 무엇인가요? ⭐⭐⭐⭐⭐
답변 :
React Query는 서버 상태를 관리하기 위한 라이브러리로, 데이터를 쉽게 가져오고 캐시하며 동기화하는 데 도움을 줍니다.
주요 특징으로는 API 호출을 간편하게 처리하는 데이터 패칭, 자동으로 데이터를 캐시하여 빠른 응답을 제공하는 캐싱, 데이터 변경 시 자동 리페치하여 최신 데이터를 제공, 데이터를 가져오는 쿼리와 변경하는 뮤테이션을 명확히 구분하여 관리할 수 있습니다.
이러한 특징들 덕분에 React Query는 데이터 패칭과 상태 관리의 효율성을 크게 향상시킵니다.
29. React Query에서 캐시의 역할은 무엇이고, 어떻게 동작하는지 설명해주세요.
⭐⭐⭐⭐⭐
답변 :
React Query에서 캐시는 서버에서 가져온 데이터를 클라이언트 측에 저장하여, 다음 요청 시 더 빠르고 효율적으로 데이터를 제공하는 역할을 합니다.
캐시는 API 호출로 가져온 데이터를 자동으로 저장하고, 동일한 쿼리 키를 사용하는 요청에 대해 캐시된 데이터를 반환합니다. 캐시된 데이터는 일정 시간 동안 유효하며, 유효 기간이 지나면 자동으로 리페치되고, 사용자가 창을 포커스하거나 네트워크 상태가 변경될 때도 업데이트됩니다. 또한, 페이지 새로 고침 시 즉시 캐시된 데이터를 렌더링한 후 백그라운드에서 최신 데이터를 가져옵니다.
특정 조건에 따라 캐시를 무효화할 수 있으며, 개발자는 캐시의 유효 기간과 삭제 정책 등을 조정할 수 있습니다. 이러한 방식으로 React Query는 네트워크 요청을 최소화하고 성능을 개선하여 사용자 경험을 향상시킵니다.
30. React Query와 Redux의 주요 차이점은 무엇이며, 어떤 상황에서 React Query를 선호하는지 말해보세요. ⭐⭐⭐⭐⭐
답변 :
Redux는 주로 클라이언트 상태(예: UI 상태, 전역 상태)를 관리하는 데 중점을 둡니다. 복잡한 애플리케이션에서 다양한 상태를 관리하고, 이를 중앙 집중식 스토어에서 관리하도록 설계되었습니다. 또한, 데이터를 가져오는 로직을 별도로 작성해야 하며, 캐싱 기능은 기본적으로 제공되지 않습니다. 개발자가 직접 API 요청을 관리해야 합니다. 비동기 작업을 처리하기 위해 미들웨어(thunk, saga 등)를 사용해야 하며, 설정이 복잡할 수 있습니다.
React Query는 서버 상태(예: API 데이터, 원격 데이터)를 관리하는 데 최적화되어 있습니다. 데이터 패칭, 캐싱, 동기화, 업데이트 등에 초점을 맞추고 있습니다. 그리고 데이터 패칭과 캐싱을 자동으로 처리하며, 비동기 쿼리와 뮤테이션을 간편하게 사용할 수 있습니다. 데이터의 생명 주기를 관리하는 다양한 기능이 내장되어 있습니다. 비동기 요청을 간단하게 처리할 수 있으며, useQuery와 useMutation 훅을 통해 쉽게 사용할 수 있습니다.
React Query를 선호하는 상황은 API에서 데이터를 주로 가져오고, 이를 클라이언트에서 캐시하고 동기화해야 하는 경우 React Query가 더 적합하며 데이터 패칭과 업데이트를 간편하게 처리해야 할 때, React Query의 훅을 사용하면 효율적입니다. 그리고 여러 API 요청을 효율적으로 관리하고, 리페치 및 오류 처리를 간편하게 하고 싶을 때 React Query가 유리합니다.
31. useQuery와 useMutation 훅의 용도 ⭐⭐⭐⭐⭐
답변:
useQuery: 데이터를 가져오는 데 사용되며, 서버 상태를 관리하고 캐싱 및 자동 리페치 기능을 제공합니다.
useMutation: 서버에 데이터를 추가, 수정 또는 삭제하는 데 사용되며, 상태 관리 및 관련 쿼리의 리페치를 지원합니다.
Typescript 면접 질문
32. 타입스크립트를 사용하는 이유에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변:
타입스크립트(TypeScript)는 자바스크립트를 기반으로 한 정적 타입 프로그래밍 언어로 정적 타입 검사를 통해 런타임 오류를 줄이고 코드 안정성을 높이며 타입 정의를 통해 코드의 가독성과 유지보수성을 향상시킵니다 그리고 강력한 IDE 지원으로 자동 완성 및 타입 힌트를 제공하여 개발 생산성을 높입니다. 마지막으로 기존 자바스크립트 프로젝트에 점진적으로 도입할 수 있어 유연성이 높습니다.
33. Type과 Interface의 차이점에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변:
Type은 변수나 함수의 다양한 사용자 정의 타입을 정의하는 데 사용되고, Interface는 주로 객체의 구조를 정의하는 데 적합합니다.
Type은 선언 병합을 지원하지 않지만, Interface는 동일한 이름의 인터페이스를 여러 번 정의할 수 있어 속성이 병합됩니다.
Type은 교차 타입을 사용하여 다른 타입을 결합할 수 있고, Interface는 extends 키워드를 사용하여 다른 인터페이스를 상속할 수 있습니다.
34. 제네릭에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변:
제네릭(Generics)은 타입스크립트에서 제공하는 기능으로, 데이터 타입에 대한 유연성과 재사용성을 높이는 데 도움을 줍니다. 제네릭을 사용하면 함수, 클래스, 인터페이스 등에서 특정 타입을 미리 정하지 않고, 사용 시점에 타입을 지정할 수 있습니다. 이를 통해 다양한 타입에 대해 동일한 로직을 적용할 수 있습니다.
35. 제네릭 유틸리티 타입에 대해 설명해주세요. ⭐⭐⭐⭐⭐
답변:
제네릭 유틸리티 타입(Generic Utility Types)은 타입스크립트에서 제공하는 내장 타입으로, 제네릭을 활용하여 다른 타입을 변형하거나 조작하는 데 유용합니다. 이러한 유틸리티 타입은 반복적인 작업을 줄이고, 코드의 가독성과 유지보수성을 향상시키는 데 도움을 줍니다.
주요 제네릭 유틸리티 타입
1) Partial<T> : 주어진 타입의 모든 속성을 선택적으로 만듭니다.
interface User {
id: number;
name: string;
email: string;
}
const updateUser: Partial<User> = {
name: "Alice", // email과 id는 선택적
};
2) Required<T>: 주어진 타입의 모든 속성을 필수로 만듭니다.
interface User {
id?: number;
name?: string;
}
const user: Required<User> = {
id: 1,
name: "Bob", // id와 name 모두 필수
};
3) Readonly<T> : 주어진 타입의 모든 속성을 읽기 전용으로 만듭니다.
4) Record<K, T> : 특정 키 타입 K와 값 타입 T로 구성된 객체 타입을 생성합니다.
type UserRoles = "admin" | "user" | "guest";
const roles: Record<UserRoles, string> = {
admin: "Administrator",
user: "Regular User",
guest: "Guest User",
};
5) Omit<T, K> : 주어진 타입 T에서 특정 속성 K를 제외한 새로운 타입을 생성합니다.
interface User {
id: number;
name: string;
email: string;
}
type UserWithoutEmail = Omit<User, "email">; // { id: number; name: string; }36. 타입가드에 대해 설명해주세요. ⭐⭐⭐
답변 :
타입 가드는 타입스크립트에서 변수의 타입을 좁히고 구체화하는 방법으로, 런타임에 타입을 안전하게 검사하고 사용할 수 있도록 합니다. typeof, instanceof, 사용자 정의 타입 가드, in 연산자 등을 사용하여 다양한 상황에서 타입을 명확히 할 수 있습니다. 이를 통해 코드의 타입 안전성을 높이고, 더 나은 개발 경험을 제공합니다.
NextJS 면접 질문
37. 프레임워크와 라이브러리 차이에 근거하여 React.js와 Next.js를 설명해주세요.
⭐⭐⭐⭐
답변 :
Next.js는 React.js를 기반으로 하는 프레임워크이며, React.js 자체는 UI 구성을 위한 라이브러리입니다.
Next.js는 React.js의 기능을 확장하여 웹 애플리케이션 개발에 필요한 다양한 기능과 구조를 제공하는
반면, React.js는 기본적인 UI 구성 기능만을 제공합니다.
- 자동 라우팅: 파일 기반의 라우팅을 지원해 파일을 특정 폴더에 추가하면 자동으로 해당 경로에 맞는 페이지가 생성됩니다.
- API 라우팅: Next.js에서는 간단한 API 서버도 함께 만들 수 있어 프론트엔드와 백엔드의 통합 개발이 가능합니다.
- 이미지 최적화: Next.js는 자동으로 이미지 크기를 조절하고 웹 성능을 최적화해줍니다.
- 페이지 라우팅 (Pages Routing)에서는 서버 사이드 렌더링(SSR) 및 정적 사이트 생성(SSG) 등을 지원하여 SEO 최적화와 초기 로딩 속도를 개선합니다.
- 그리고 앱 라우팅 (App Routing)에서는 서버 컴포넌트와 클라이언트 컴포넌트 기능을 제공하여 기본적으로 모든 컴포넌트는 서버 컴포넌트로 처리되며, 클라이언트 측 기능이 필요한 경우 use client 지시어를 사용하여 클라이언트 컴포넌트로 변환할 수 있습니다.
38. Next.js에서 제공하는 렌더링 기법에는 어떤 것들이 있나요? 각각의 특징과 구현방법을 간단히 설명해주세요. ⭐⭐⭐⭐⭐
답변 :
1. 클라이언트 사이드 렌더링 (Client-Side Rendering, CSR) :
클라이언트 측에서 JavaScript를 사용하여 페이지를 렌더링하는 방식입니다. 초기에는 최소한의 HTML만 서버에서 전달하고, 이후에 JS Bundle 전체 JS 코드를 브라우저에 보내 브라우저에서 JS 파일을 실행해 컨텐츠를 렌더링하고 그제서야 유저는 컨텐츠가 포함된 화면을 보게 됩니다.
사용자 상호작용에 따라 데이터를 동적으로 가져오는 경우에 유용합니다. 그러나 JS Bundle 전체 파일을 한번에 보낸다는 특징이 있어 초기 로딩(초기 접속)에는 지연이 있어 첫 화면이 표시되기까지 시간이 걸린다는 단점이 있습니다.
2. 서버 사이드 렌더링 (Server-Side Rendering, SSR)
사용자의 요청 시마다 서버에서 HTML을 동적으로 생성하여 전송하는 방식입니다.
저가 접속요청을 보내면 서버측에서 화면에 필요한 HTML 페이지를 생성하여 브라우저 측에 전달합니다, CSR 방식에서 보다 빠르게 컨텐츠가 렌더링 된 화면을 볼 수 있게됩니다.
이후 Next 서버가 브라우저에 후속으로 해 화면과 상호작용을 위한 자바스크립트 코드를 번들링 해서 브라우저에 보내주게 됩니다. 그럼 브라우저는 서버에서 받은 JS 코드를 직접 실행(하이드레이션)해서 현재 화면에 렌더링된 HTML 요소들과 연결해주어 화면과 상호작용할 수 있게 됩니다.
요청할 때마다 서버에서 HTML을 생성하여 클라이언트에 전달합니다. 최신 데이터를 제공할 수 있어 동적인 콘텐츠에 유리합니다. 초기 로딩 속도는 SSG보다 느릴 수 있지만, 데이터가 항상 최신 상태로 유지됩니다.
3. 정적 사이트 생성 (Static Site Generation, SSG) :
빌드 타임에 미리 HTML 파일을 생성하여 요청 시 정적 파일을 제공하는 방식
SSG 방식은 빌드 타임에 미리 페이지를 사전 렌더링 해두는 방식입니다. npm run build 명령어로 빌드할 때, 사전 렌더링을 진행해서 페이지를 미리 딱 한번만 생성하고 더이상 페이지를 생성하지 않습니다.
빌드가 완료된 이후에 실제 넥스트 앱을 가동하면 브라우저가 접속 요청을 보내면 넥스트 서버는 빌드 타임에 미리 만들어둔 페이지를 바로 제공하게 된다. 그리고 그럼으로써 사용자는 매우 빠른 시간 안에 완성된 화면을 볼 수 있게 됩니다. 콘텐츠가 자주 변경되는 사이트에는 적합하지 않습니다. 페이지를 업데이트하려면 다시 빌드해야 합니다.
4. 인크리멘탈 정적 재생성 (Incremental Static Regeneration, ISR)
ISR 는 SSG의 확장으로, 정적 페이지를 생성하되 특정 시간 간격으로 페이지를 재생성하는 방식입니다. revalidate 라는 새로운 프로퍼티를 추가해준 뒤, 값으로 몇 초 주기로 이 페이지를 다시 생성할 건지 페이지의 유통기한을 설정해주면 됩니다.
39. FCP, TTI, hydration의 관계를 설명해주세요. ⭐⭐⭐⭐
FCP (First Contentful Paint)는 사용자가 웹 페이지를 요청한 후 첫 번째 시각적 피드백을 받을 때까지의 시간을 나타냅니다.
TTI (Time to Interactive)는 사용자가 최초로 페이지와 상호작용 할 때 까지 걸리는 시간입니다.
pre-rendering 과정을 통해 사용자와 상호작용하는 부분을 제외한 껍데기만을 먼저 브라우저에게 제공하여 FCP가 빠르게 일어나며, hydration 은 사전 렌더링을 통해 전달 받은 HTML 과 상호작용할 수 있도록 해당 페이지에 필요한 자바스크립트 코드와 연결되는 과정을 수화(Hydration) 라고 하는데 이를 통해 페이지와 상호작용이 가능해집니다.
40. 코드스플리팅이란 무엇인가요? ⭐⭐⭐⭐⭐
**코드 스플리팅 (Code Splitting)**은 웹 애플리케이션의 성능을 개선하기 위해 사용하는 기법으로, 애플리케이션의 JavaScript 코드를 여러 개의 작은 청크로 나누어 필요한 시점에만 로드하는 방법입니다. 이 방식은 초기 로딩 시간을 줄이고, 사용자 경험을 향상시키는 데 도움을 줍니다.
Next.js에서는 애플리케이션에 존재하는 모든 페이지 컴포넌트들을 페이지별로 분리(스플리팅)해서 저장을 미리 마쳐두기 때문에 JS 번들이 서버에서 클라이언트로 전달될 때에는 모든 페이지에 필요한 코드들이 전달되는게 아니라, 필요한 부분만 전달하게 됩니다.
41. Next.js에서 <Link> 컴포넌트의 prefetching 기능의 장점은 무엇인가요?
⭐⭐⭐⭐
<Link> 컴포넌트의 prefetching 기능은 사용자가 링크를 클릭하기 전에 해당 페이지의 데이터와 코드를 미리 로드합니다. 미리 데이터와 코드를 가져오기 때문에, Link를 클릭했을 때 아주 빠르게 페이지를 보여줄 수 있어요.
42. 서버 컴포넌트와 클라이언트 컴포넌트은 무엇이며 주된 차이점은 무엇인가요?
⭐⭐⭐⭐⭐
서버 컴포넌트는 애플리케이션의 서버 부분에서 렌더링되는 컴포넌트로 클라이언트에 HTML 형태로 전달됩니다. 클라이언트 측에서는 JavaScript가 실행되지 않으며, 서버에서 데이터를 가져와서 HTML을 생성합니다.
서버 컴포넌트는 서버에서 동작하기 때문에 데이터 패칭 같이 서버 측에서 동작하는 것들은 사용이 가능하지만 반대로 브라우저 측에서 동작하는 useEffect 같은 리액트 Hooks는 사용할 수 없다.
클라이언트 컴포넌트는 "use client" 선언을 통해 브라우저에서 실행되며, UI 상호작용 및 동적 데이터 관리가 필요할 때 사용됩니다.
Frontend 면접 질문
43. 브라우저는 어떻게 동작 하나요? ⭐⭐⭐⭐
사용자가 주소창에
URL을 입력하면 브라우저는 도메인 이름을 IP 주소로 변환하기 위해 DNS(Domain Name System) 서버에 요청을 보냅니다. DNS 서버가 IP 주소를 반환하면 브라우저는 해당 서버에 연결하여 HTTP 요청을 생성하고, 웹 서버에 전송합니다. 웹 서버는 요청을 처리하고 요청한 리소스(예: HTML 문서, 이미지 등)를 포함한 HTTP 응답을 브라우저에 반환합니다.
브라우저는 서버로부터 받은 HTML 문서를 파싱(parse)하여 DOM(Document Object Model) 트리를 생성하고, HTML 내의 CSS를 파싱하여 CSSOM(CSS Object Model) 트리를 생성합니다. 이 두 트리(DOM과 CSSOM)는 결합되어 렌더 트리를 형성합니다.
이후, 브라우저는 렌더 트리를 기반으로 레이아웃(layout) 단계를 수행하여 각 요소의 크기와 위치를 계산합니다. 레이아웃이 완료되면, 브라우저는 실제로 화면에 요소를 그리는 페인팅(painting) 단계를 진행하며, 복잡한 웹 페이지의 경우 여러 레이어로 나누어 요소를 그린 후 최종적으로 하나의 화면으로 합쳐지는 합성(compositing) 과정을 거칩니다.
또한, HTML 문서 내에 포함된 JavaScript 코드가 실행되며, JavaScript는 DOM 및 CSSOM을 조작할 수 있어 사용자 상호작용에 따라 페이지를 동적으로 업데이트합니다. 마지막으로, 사용자가 페이지와 상호작용하면 브라우저는 해당 이벤트를 처리하고 필요에 따라 DOM을 업데이트합니다.
꼬리 및 연관 질문 : 리플로우와 리페인트에 대해 설명하시오.
리플로우란, 웹 페이지 내에서 요소의 위치 또는 크기에 변화가 있을 때, 변화된 레이아웃을 다시 계산하여 렌더 트리에 적용하는 과정을 의미합니다.
width, heught, padding, margin 와 같은 크기 관련 속성 / position, top, left 와 같은 위치 관련 속성,
display, flex 와 같은 레이아웃 관련 속성 / font-size, font-weight 와 같은 폰트 크기 관련 속성이 리플로우를 유발하는 속성입니다.
리페인트란, 웹 페이지 내에서 요소의 시각적인 표현에 변화가 있을 때, 변화된 시각적 표현을 다시 계산하여 렌더 트리에 적용하는 과정을 의미합니다.
color, background-color 와 같은 색상 관련 속성 / border-color, border-radius 와 같은 테두리 관련 속성이 리페인트를 유발하는 속성입니다.
꼬리 및 연관 질문 : 리플로우와 리페인트의 성능상 차이점을 설명해주세요.
부모 노드의 레이아웃 변화는 자식 노드의 레이아웃까지 영향을 미치기 때문에 리페인트와 달리 리플로우가 발생하면 하위 렌더 트리를 다시 계산하고 재구성하는 과정이 필요합니다. 따라서 리플로우는 그 자체만으로 부하가 큰 작업입니다.
또한 리플로우가 발생하면 일반적으로 리페인트도 다시 발생하기 때문에 성능에 큰 영향을 끼친다고 할 수 있으며, 렌더링 성능을 최적화하기 위해서는 리플로우를 최소화해야 합니다.
44. Webpack, Babel, Polyfill에 대해 설명해주세요.⭐⭐⭐
Webpack은 모듈 번들링과 최적화를 지원하는 도구
Babel은 최신 자바스크립트 코드를 구형 브라우저에서도 실행할 수 있도록 변환하는 도구
Polyfill은 특정 기능이나 API의 호환성을 제공하는 코드입니다.
45. CORS는 무엇인지 설명해주세요. ⭐⭐⭐⭐⭐
CORS는 Cross-Origin Resource Sharing의 약자로 교차 출처 리소스 공유라고도 부릅니다.
SOP에 의해 제한된 교차 출처 간 리소스 공유를 허용하기 위한 방법입니다.애플리케이션의 요구 사항이 복잡해지면서 다른 도메인의 리소스를 활용하는 경우가 많아졌기 때문에 등장한 프로토콜로 다른 도메인의 리소스를 활용하는 경우가 많아졌기 때문에 등장한 프로토콜로 서버에서 CORS 관련 헤더를 설정하여 다른 도메인에서의 리소스 요청을 허용할 수 있습니다.
CORS 에러는 CORS 헤더를 적절히 설정하지 않은 상태에서 교차 출처 리소스를 요청하는 경우 발생할 수 있습니다.
꼬리 및 연관 질문 : SOP란 무엇인지 설명해주세요.
SOP는 Same Origin Policy의 약자로, 동일 출처 정책을 의미합니다. 현재 출처와 동일한 출처의 리소스만 접근할 수 있도록 하는 정책입니다.
여기서 동일 출처란 도메인과 프로토콜 포트 번호가 모두 같은 경우를 의미하며 하나라도 다를 경우 동일 출처 정책에 의해 리소스 접근이 제한됩니다.
꼬리 및 연관 질문 : SOP가 없을 경우 가능한 보완 취약점은 무엇인가요?
사용자 인증 정보에 해당하는 세션 ID 같은 정보들이 쿠키에 포함되어 있을 수 있기 때문에 이 세션 정보를 탈취하여 Cross Site Scripting 혹은, CSRF와 같은 해킹 공격에 이용할 수 있습니다.
SOP 정책을 통해 리소스를 다른 도메인에서 접근하지 못하도록 제한한다면 이러한 해킹 공격을 어느 정도 완화할 수 있습니다.
꼬리 및 연관 질문 : CORS 프로토콜이 동작하는 원리를 설명하세요.
서버는 응답 처리 코드에서 CORS 관련 헤더 설정을 할 수 있습니다.
이 헤더를 통해 요청을 허용할 도메인과, HTTP 메서드, 그리고 요청 헤더의 종류를 정의할 수 있습니다. 아후 브라우저에서 서버로 리소스를 요청할 때, 이 헤더에 설정한 정보와 일치하지 않는다면 브라우저에서 CORS 에러가 발생하는 것 입니다.
46. 이벤트 루프와 태스크 큐에 대해 설명해주세요. ⭐⭐⭐⭐⭐
이벤트 루프는 JavaScript의 실행 환경에서 비동기 작업과 콜백을 관리하는 메커니즘입니다. JavaScript는 싱글 스레드로 동작하기 때문에, 동시에 여러 작업을 처리할 수 없지만, 이벤트 루프를 통해 비동기 작업을 효율적으로 처리할 수 있습니다.
이벤트 루프 작동방식으로는 먼저 함수 호출 시 해당 함수가 스택에 쌓이고, 실행이 완료되면 스택에서 제거됩니다. 그 다음 이벤트 루프는 콜 스택이 비어 있으면, 태스크 큐에서 대기 중인 첫 번째 작업을 콜 스택으로 가져와 실행합니다. 이 과정을 반복하면서 비동기 작업을 처리합니다.
태스크 큐는 비동기 작업의 콜백 함수가 대기하는 큐입니다. 이 큐는 JavaScript가 실행할 수 있는 작업을 담고 있으며 이벤트 루프와의 상호작용하여 태스크 큐에서 대기 중인 태스크를 콜 스택으로 이동시켜 실행합니다.
47. 쿠키, 세션, 웹 스토리지
쿠키(Cookie)
브라우저에 저장되는 Key 와 Value 로 작은 크기의 문자열
- 4KB의 크기 제한이 있으며 일정 시간이 지나면 만료되도록 설정할 수 있고 만료 후에는 사용자의 컴퓨터에서 삭제됩니다.
- HTTP 요청 시 따로 설정하지 않아도 자동으로 전달됩니다.
세션(Session)
세션은 서버 측에서 클라이언트를 식별하기 위해 사용하는 기술입니다.
- 클라이언트가 처음 서버에 접속하면, 서버는 고유한 세션 ID를 생성하고 이를 클라이언트에게 전달합니다. 이 세션 ID는 주로 쿠키를 통해 클라이언트에게 전달되며, 클라이언트는 이후 요청마다 세션 ID를 서버에 전달하여 자신을 식별합니다.
- 서버는 세션 ID를 통해 클라이언트의 정보를 서버 메모리 또는 데이터베이스에 저장하고 관리하며, 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지합니다.
웹스토리지(Web Storage)
클라이언트에 데이터를 저장할 수 있도록 HTML5부터 추가된 저장소
- key와 value 쌍의 형태로 데이터 저장
- 로컬 스토리지와 세션 스토리지가 존재
- 도메인 단위로 접근이 제한되는 CORS 특성 덕분에 CSRF로부터 안전
로컬 스토리지(localStorage)
사용자가 데이터를 지우지 않는 이상, 브라우저나 OS를 종료해도 계속 브라우저에 남아있음 (영구성)
세션 스토리지(sessionStorage)
데이터가 오리진 뿐만 아니라 브라우저 탭에도 종속되기 때문에, 윈도우나 브라우저 탭을 닫을 경우 제거
48. DOM의 개념을 설명해주세요. ⭐⭐⭐⭐
HTML 이나 XML 같은 마크업 언어로 작성된 문서를 자바스크립트와 같은 프로그래밍 언어가 조작할 수 있도록 하는 인터페이스를 의미합니다.
DOM은 계층적 구조를 가진 노드 트리로 구성됩니다.꼬리 및 연관 질문 : DOM 은 왜 필요한가요?
동적인 웹 페이지를 구현하려면 자바스크립트와 같은 프로그래밍 언어가 문서에 접근하고, 제어할 수 있는 수단이 있어야 하지만 마크업 언어로 작성된 문서에는 이러한 수단이 없습니다. 따라서 문서에 접근하고 제어할 수 있는 수다인 DOM 이 필요합니다.
꼬리 및 연관 질문 : DOM 을 통해 어떤 동작을 할 수 있는지 예를 들어주세요.
<button> element가 클릭되었을 때, 특정 함수를 호출하도록 Event Handler 를 추가할 수 있고 웹 페이지 내에 새로운 요소를 추가하거나, 삭제, 수정할 수 있습니다.
꼬리 및 연관 질문 : DOM 은 왜 계층적 구조로 표현하는지 설명해주세요.
계층적 구조에서는 노드들 간의 관계가 부모, 자식, 형제 등으로 명확하게 정의됩니다. 이는 노드의 추가, 제거, 이동 작업을 쉽게할 수 있도록 도와줍니다.
또한 이벤트가 발생한 요소로부터 이벤트가 올라가는 이벤트 버블링, 반대로 이벤트가 내려가는 이벤트 캡쳐링 동작은 계층적 구조에서 효율적으로 동작하기 때문에, DOM을 계층적 구조로 표현하는 것입니다.
49. 이벤트 버블링과 이벤트 캡처링에 대한 예시를 들어주세요. ⭐⭐⭐⭐⭐
이벤트 버블링과 이벤트 캡처링은 브라우저에서 이벤트가 전파되는 방식입니다.
이벤트 버블링: 이벤트가 발생한 타깃 요소부터 부모 요소를 향해 전파되는 방식입니다. 예를 들어, 버튼 클릭 이벤트가 발생하면, 해당 이벤트는 버튼에서 시작하여 상위의 부모 요소부터 상위의 부모 요소로 차례로 전파됩니다.
이벤트 캡처링: 최상위 요소부터 이벤트가 발생한 타깃 요소까지 전파되는 방식입니다. 캡처링은 이벤트가 전파될 때, 먼저 상위 요소에서부터 하위 요소로 내려가는 과정에서 이벤트를 처리합니다.
이러한 버블링과 캡처링 같이 전파되는 현상을 막고 싶으면 stopPropagation() 메소드를 사용하여 이벤트가 더 이상 전파되지 않도록 막아줍니다.
또한, 버블링 현상에 의한 폼 제출 및 링크 클릭 방지하고 싶은 경우, preventDefault() 메서드와 같이 이벤트의 기본 동작을 방지하는 메서드를 사용합니다.
50. SPA란 무엇인가요? ⭐⭐⭐⭐⭐
SPA(Single Page Application)는 웹 애플리케이션의 한 형태로, 단일 HTML 페이지에서 동작하며, 페이지 간의 전환이 빠르고 매끄럽게 이루어지는 웹 애플리케이션입니다.
전통적인 웹 애플리케이션에서는 각 페이지를 요청할 때마다 전체 페이지를 새로 로드하지만, SPA에서는 필요한 데이터만 서버와 비동기적으로 교환하여 페이지의 일부만 업데이트합니다.
51. ES6 문법에 대해서 아는대로 답변해주세요. ⭐⭐⭐⭐
ES6 문법에는 let과 const 가 있으며 함수를 간결하게 작성할 수 있는 화살표 함수 문법과 템플릿 리터럴 문법을 통해 문자열을 작성할 때 백틱(`)을 사용하여 여러 줄 문자열과 변수 삽입을 쉽게 할 수 있습니다
또한, 디스트럭처링 할당으로 배열이나 객체의 값을 쉽게 추출하여 변수에 할당이 가능하도록 했고, 함수의 매개변수로 전달된 인자를 배열로 수집하는 나머지 매개변수와 배열이나 객체를 펼치는 데 사용되는 전개 연산자 그리고 객체 지향 프로그래밍을 위한 클래스 등을 도입했으며 ES6에서는 모듈 시스템을 도입하여, 코드의 재사용성과 유지보수성을 높였습니다. export와 import를 사용하여 모듈을 정의하고 가져올 수 있습니다.
마지막으로 비동기 프로그래밍을 위한 Promise 객체가 도입되어, 비동기 작업의 결과를 처리하는 방법이 개선되었습니다.
52. 동기식 방법과 비동기식 방법의 차이점에 대해서 답변해주세요. ⭐⭐⭐⭐⭐
동기식 방법과 비동기식 방법은 프로그램의 실행 흐름과 작업 처리 방식에 따라 구분됩니다.
먼저 동기식 방법은 작업이 순차적으로 실행됩니다. 즉, 하나의 작업이 완료될 때까지 다음 작업이 시작되지 않습니다. 이 방식은 코드가 위에서 아래로 순차적으로 실행되며, 각 작업이 완료되기를 기다립니다.
비동기식(Asynchronous) 방법은 작업이 동시에 진행될 수 있습니다. 즉, 하나의 작업이 완료되기를 기다리지 않고, 다음 작업이 바로 시작됩니다. 비동기 작업은 주로 콜백, 프로미스, async/await 패턴 등을 통해 구현됩니다.
53. 웹사이트 성능 최적화에는 어떤 방법이 있나요?⭐⭐⭐⭐⭐
웹사이트 성능 최적화 방법에는 다음과 같은 방식이 있습니다.
먼저, 이미지 최적화를 위해 WebP 저용량 파일 형식을 선택하거나 srcset 속성을 사용하여 다양한 해상도의 이미지를 제공함으로써 화면 크기에 맞는 최적의 이미지가 로드되도록 합니다. 다음으로, 코드 최적화를 통해 공백과 주석 등 쓸데없는 코드를 제거하여 코드 파일 크기를 줄이거나 필요한 파일만 로드하도록 하는 코드 스플리팅을 활용합니다.
또한, **콘텐츠 전송 네트워크(CDN)**를 사용하여 사용자와 가장 가까운 서버에서 콘텐츠를 제공함으로써 로딩 시간을 줄이고, 비동기 및 지연 로딩으로 <script> 태그에 async 또는 defer 속성을 추가하여 페이지 로딩 중 스크립트가 차단되지 않도록 하며, loading="lazy" 속성을 사용해 사용자가 스크롤할 때 필요한 이미지를 로드하도록 설정하여 초기 로딩 속도를 개선할 수 있습니다.
마지막으로, 서버 성능을 최적화하기 위해 적절한 호스팅 서비스를 선택하여 웹사이트의 전반적인 성능을 향상시킬 수 있습니다.
54. HTTP 와 HTTPS 에 대해 설명해주세요. ⭐⭐⭐⭐
HTTP는 HyperText Transfer Protocol의 약자로, 클라이언트와 서버 간 통신을 위한 프로토콜입니다. HTTP는 기본적으로 포트 80을 사용하며 데이터를 암호화하지 않고 전송하므로, 중간에 데이터가 노출될 수 있습니다. HTTP는 상태 비저장(stateless) 프로토콜로, 각 요청은 이전 요청의 상태를 기억하지 않습니다.
HTTPS는 HTTP의 보안 버전으로, 데이터를 안전하게 전송하기 위해 SSL(Secure Sockets Layer) 또는 TLS(Transport Layer Security) 프로토콜을 사용합니다. HTTPS는 포트 443을 사용하며 데이터를 암호화하여 전송하므로, 중간에서 데이터가 도청되거나 변조되는 것을 방지합니다.
55. Cascading에 관해서 설명해주세요. ⭐⭐⭐⭐
Cascading은 스타일 규칙의 적용 순서를 결정하는 방식을 의미합니다.
이 개념은 다음의 세 가지 주요 요소에 의해 결정됩니다.
1. 우선순위 (Specificity) :
인라인 스타일 (예: style 속성) > ID 선택자 (예: #example) > 클래스 선택자, 속성 선택자, 가상 클래스 선택자 (예: .example, [type="text"], :hover) > 태그 선택자 (예: div, p) > 유니버설 선택자 (*).
2. 출처 (Source Order) :
CSS 파일의 로딩 순서에 따라 스타일의 적용 순서가 달라질 수 있습니다. 동일한 우선순위를 가진 규칙이 여러 개 있을 경우, 나중에 로드된 규칙이 이전 규칙을 덮어씌웁니다.
.example {
color: blue;
}
.example {
color: red; /* 이 규칙이 적용됨 */
}
3. !important :
CSS 선언에 !important를 추가하면 해당 스타일의 우선순위가 높아집니다. 다른 모든 규칙보다 우선 적용되지만, 일반적으로는 사용을 자제하고, 필요한 경우에만 사용해야 합니다.
56. Tailwind CSS와 같은 Utility-first CSS 프레임워크를 사용하는 이유는 무엇인가요? 어떤 장점이 있나요?⭐⭐⭐⭐⭐
Tailwind CSS와 같은 Utility-first CSS 프레임워크를 사용하는 이유는 다양한 유틸리티 클래스를 제공하여, CSS를 작성하는 대신 HTML에서 클래스 이름만 추가함으로써 빠르게 스타일을 적용할 수 있기 때문입니다. 유틸리티 클래스를 사용하면 스타일을 재사용하고 구성하기 쉬워, 일관된 디자인을 유지할 수 있습니다.
Tailwind는 사용자가 필요에 따라 색상, 폰트, 간격 등을 쉽게 커스터마이즈할 수 있도록 설정 파일을 제공하며, 모바일 우선 접근 방식을 지원하여 반응형 디자인을 위해 다양한 뷰포트에 맞는 유틸리티 클래스를 제공합니다.
또한, Tailwind는 사용하지 않는 CSS 클래스를 자동으로 제거하는 Purge 기능을 통해 최종 CSS 파일의 크기를 줄여 페이지 로딩 속도를 개선합니다. 이러한 장점들 덕분에 Tailwind CSS는 효율적인 웹 개발을 지원합니다.
57. CSS-in-JS의 장점과 단점은 무엇인가요? ⭐⭐⭐
CSS-in-JS는 자바스크립트 파일 내에서 CSS 스타일을 정의하고 사용하는 방식입니다. 이 접근 방식은 컴포넌트 기반 라이브러리(예: React, Vue)와 함께 사용되며, 스타일을 컴포넌트와 밀접하게 결합하여 모듈화된 스타일링을 가능하게 합니다.
장점으로는 스타일과 컴포넌트를 함께 관리하여 코드의 가독성이 향상되며 동적 스타일링을 제공하 상태에 따라 스타일을 쉽게 변경할 수 있습니다. 그리고 스타일이 컴포넌트와 함께 정의되므로, 유지보수가 용이합니다.
단점으로는 CSS-in-JS는 런타임에 스타일을 계산하므로, 성능에 영향을 줄 수 있으며, 학습 곡선이 있을 수 있습니다.
58. CSS Modules와 CSS-in-JS의 차이점과 각각의 장단점에 대해 설명해보세요.
⭐⭐⭐
CSS Modules는 CSS 파일을 모듈화하여 사용하는 방법으로
장점으로는 자동으로 고유한 클래스 이름이 생성되어 이름 충돌 방지되고 간단한 사용방법이 있으며 단점으로는 동적으로 스타일을 변경하거나 조건부 스타일링을 구현하기 어렵습니다.
CSS-in-JS는 자바스크립트 파일 내에서 CSS 스타일을 정의하고 사용하는 방식으로
장점에는 자바스크립트의 변수와 함수를 사용하여 스타일을 동적으로 정의할 수 있으며 스타일이 컴포넌트와 함께 정의되어, 유지보수와 재사용이 용이합니다. 그러나 스타일이 런타임에 계산되므로, 초기 로딩 시 성능이 저하될 수 있습니다.
59. bundle의 사이즈를 줄이려면 어떻게 해야 하나요? ⭐⭐⭐
코드 스플리팅 (Code Splitting), 트리 쉐이킹 (Tree Shaking), Gzip 압축 사용, 이미지 최적화, 외부 라이브러리 최적화, Lazy Loading (지연 로딩) 등을 활용합니다.
60. 100개의 API 호출이 있다고 했을 때, 오류 처리를 어떻게 할 것인가. ⭐⭐⭐⭐
API 호출을 비동기로 처리하고, 각 호출에 대한 오류를 적절히 처리하기 위해 Promise를 사용합니다.
예를 들어 Promise.all 사용하여 모든 API 호출을 동시에 처리한 후, 결과를 한 번에 처리합니다. 이 경우, 하나의 호출이 실패하면 전체가 실패할 수 있습니다. 아니면 Promise.allSettled 사용하여 모든 API 호출의 결과를 기다리되, 성공과 실패를 모두 처리합니다. 이 방법은 모든 호출 결과를 개별적으로 확인할 수 있습니다.
일시적인 오류(예: 네트워크 문제)로 인해 API 호출이 실패할 수 있습니다. 이런 경우에는 재시도 로직을 구현하여 호출을 다시 시도할 수 있으며 로깅 시스템 사용하여 API 호출의 오류를 기록하고 모니터링하여 문제의 원인을 분석하고, 시스템의 안정성을 높입니다.
61. 2개의 변수가 있다고 했을 때 변수에 담긴 데이터를 서로 뒤바꾸고 싶을 때 어떻게 처리할 것인가. ⭐⭐⭐
1. 기본적인 스왑 (임시 변수 사용) 방식
let a = 5;
let b = 10;
let temp = a; // a 값을 temp에 저장
a = b; // b 값을 a에 할당
b = temp; // temp 값을 b에 할당
console.log(a); // 10
console.log(b); // 5
2. 배열 사용
let a = 5;
let b = 10;
[a, b] = [b, a]; // 배열 구조 분해 할당 사용
console.log(a); // 10
console.log(b); // 562. position 속성을 나열해주세요. ⭐⭐⭐
static: 기본값으로 요소는 문서 흐름에 따라 위치가 결정됩니다.
relative: 자신의 원래 위치에서 상대적으로 이동합니다.
absolute: 가장 가까운 위치 지정 조상을 기준으로 절대적으 위치합니다.
fixed: 뷰포트를 기준으로 고정되며 스크롤 시에도 위치가 고정됩니다.
sticky: 스크롤 시 특정 위치에 고정되며, 그 위치에 도달하기 전까지는 문서 흐름에 따라 위치합니다.
63. RTK를 통한 클라이언트 상태 관리와 React Query를 통한 서버 상태 관리를 조합하여 사용한 이유에 대해 설명해주세요.
RTK를 통한 클라이언트 상태 관리와 React Query를 통한 서버 상태 관리를 조합해서 사용한 이유는
클라이언트 상태와 서버 상태를 명확하게 구분하여 관리하므로, 각 상태의 변화에 대한 이해와 유지보수가 쉬워지고 React Query는 서버 데이터의 캐싱과 자동 갱신을 통해 성능을 최적화하며, RTK는 클라이언트 상태의 빠른 업데이트를 가능하게 하여 클라이언트와 서버 상태를 각각 최적화된 방법으로 관리하여 클라이언트와 서버 상태를 효율적으로 관리할 수 있습니다.
64. XSS(Cross-Site Scripting)란 무엇이며 어떻게 방지할 수 있나요?
답변: XSS는 악의적인 스크립트를 웹사이트에 주입하여 다른 사용자의 브라우저에서 실행되게 하는 공격입니다.
- Content Security Policy(CSP) 헤더 설정
- HttpOnly 쿠키 사용
65. CSRF(Cross-Site Request Forgery)에 대해 설명해주세요
답변: 사용자가 자신의 의지와 무관하게 공격자가 의도한 행위를 특정 웹사이트에 요청하게 하는 공격입니다.
- CSRF 토큰 사용
- Same-Origin Policy 준수
- SameSite 쿠키 속성 사용
프로젝트 관련 면접 질문
66. "React-Query를 사용하면서 느낀 장점은 무엇인가요? 일반 fetch나 axios와 비교했을 때 어떤 점이 좋았나요?"
React-Query의 가장 큰 장점은 캐싱 기능입니다. 일반 fetch나 axios를 사용할 때는 데이터 캐싱을 직접 구현해야 했지만, React-Query는 자체적으로 캐싱을 지원해 서버 부하를 줄일 수 있었습니다. 또한 loading, error 상태 관리가 매우 편리했고, 동일한 데이터에 대한 중복 요청을 자동으로 방지해주는 기능도 유용했습니다.
67. "캐시 적용 전후를 비교하셨는데, 성능 측정은 어떤 방식으로 진행하셨나요? 가장 인상 깊었던 개선 결과는 무엇인가요?"
AWS CloudWatch를 통해 서버의 CPU 사용률, 네트워크 트래픽, 메모리 사용률 등을 측정했습니다. 가장 인상 깊었던 결과는 네트워크 인바운드 트래픽이 85.90% 감소한 것입니다. 이는 캐시된 데이터를 재사용함으로써 불필요한 서버 요청이 크게 줄어들었다는 것을 의미합니다.
68. React-Query 라이프사이클에 대해 설명해주세요.
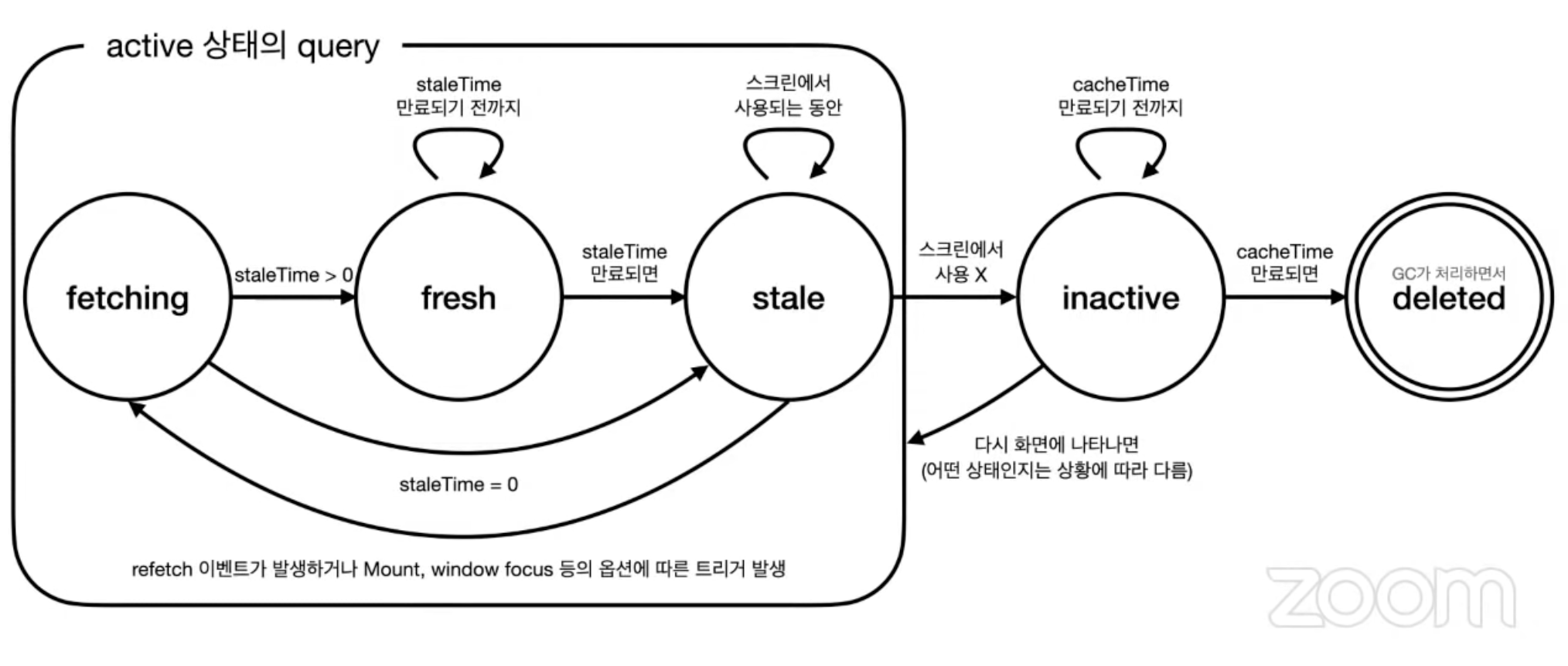
1. Fetching : 데이터를 가져오는 중인 상태
2. Fresh : 데이터가 처음 성공적으로 fetch되어 완전히 신선한 상태를 의미합니다. staleTime이라는 설정값 동안 이 상태가 유지되며, 이 기간 동안은 불필요한 재검증이 발생하지 않습니다.
3. Stale : staleTime이 경과하면 데이터는 'stale' 즉, 오래된 상태로 간주됩니다. 이 상태에서는 여러 조건에서 재검증이 발생할 수 있는데, 예를 들어 컴포넌트가 다시 마운트되거나, 윈도우에 포커스가 들어오거나, 네트워크가 재연결될 때입니다.
4. Inactive : 쿼리를 사용하던 컴포넌트가 언마운트되면 쿼리는 비활성 상태로 전환됩니다. 이 상태의 데이터는 cacheTime 동안 메모리에 유지되다가, 시간이 경과하면 가비지 컬렉션됩니다.
5. Delete : 가비지 콜렉터에 의해 캐시에서 제거된 상태.
69. "캐시 상태(Fresh, Stale, Deleted)별로 데이터 처리 방식이 다른데, 실제 사용자 경험에는 어떤 영향을 미쳤나요? 특히 Stale 상태에서 백그라운드 요청이 실패하는 경우는 어떻게 처리하셨나요?"
각 상태별로 다음과 같은 처리 전략을 수립했습니다:
- Fresh 상태: 캐시된 데이터를 즉시 보여줌으로써 사용자는 즉각적인 응답을 경험할 수 있었습니다.
- Stale 상태: 백그라운드 요청 실패 시 다음과 같은 에러 핸들링을 구현했습니다:
1. 기존 캐시 데이터를 계속 표시
2. 토스트 메시지로 업데이트 실패 알림
- Deleted 상태: 새로운 요청 실패 시 로딩 및 에러 상태를 명확히 표시
70. Redux 와 React-Query 상태관리 라이브러리 차이점에 대해 설명하시오.
Redux와 React-Query는 모두 상태 관리를 위한 라이브러리로
Redux는 애플리케이션의 전역 상태를 관리하기 위한 라이브러리입니다. 주로 클라이언트 측의 상태를 중앙 집중식으로 관리하고, 컴포넌트 간의 상태 공유를 용이하게 합니다. 그리고 Redux는 복잡한 애플리케이션에서 전역 상태 관리가 필요할 때 유용합니다.
반면, React-Query는 서버 상태를 관리하는 데 중점을 둡니다. API 호출을 통해 데이터를 가져오고, 캐싱, 동기화, 업데이트 등을 자동으로 처리하여 서버와의 상호작용을 간소화합니다. React-Query는 서버와의 데이터 통신이 많은 애플리케이션에서 특히 효과적입니다.
71. React Query의 캐싱 메커니즘에 대해 설명해주세요.
React Query의 캐싱은 다음과 같은 메커니즘으로 동작합니다.
먼저 각 쿼리는 고유한 쿼리 키를 가지며, 이 키를 기반으로 캐시를 관리합니다. 데이터를 처음 불러오면 해당 키로 캐시에 저장되고, 이후 같은 키로 요청이 들어오면 캐시된 데이터를 우선 반환합니다.
캐시된 데이터는 staleTime과 gcTime이라는 두 가지 시간 설정에 따라 관리됩니다. staleTime은 데이터가 '신선한' 상태로 유지되는 시간이고, gcTime 은 실제로 캐시에 보관되는 시간입니다.
또한 백그라운드에서 자동으로 데이터를 갱신하는 기능도 제공하여, 사용자에게는 캐시된 데이터를 보여주면서 최신 데이터로 업데이트할 수 있습니다.
72. "서버 성능 측정 시 200회 요청을 선택하신 특별한 이유가 있으신가요? 실제 프로덕션 환경에서는 어떤 방식으로 캐시 전략을 수립하실 건가요?"'
200회 요청을 선택한 이유는 다음과 같습니다:
- 통계적으로 유의미한 샘플 크기 확보
- 실제 서비스의 피크 타임 트래픽을 시뮬레이션
- 테스트의 반복 가능성과 신뢰성 확보
프로덕션 환경에서의 캐시 전략:
1. 데이터 특성에 따른 세분화된 캐시 설정
2. 정기적인 성능 모니터링 및 캐시 설정 최적화
73. "SSR의 DOM 로딩이 더 느린 것으로 나타났는데, 이를 개선하기 위한 방법을 고민해보신 적 있으신가요? 어떤 최적화 전략을 적용해볼 수 있을까요?"
1. 스트리밍 SSR 활용
- suspense 바운더리를 활용한 점진적 페이지 로드
- 우선순위가 높은 컨텐츠 먼저 전달
2. 코드 분할 및 지연 로딩
- 동적 import를 통한 컴포넌트 분할
- 초기 번들 사이즈 최소화
74. "페이지 이동 성능에서 CSR이 더 빠른 결과를 보였는데, SSR을 사용해야 하는 상황에서 페이지 이동 성능을 개선할 수 있는 방법에 대해 어떻게 생각하시나요?"
1. ISR(Incremental Static Regeneration) 활용
- 정적 페이지 생성과 주기적 업데이트 조합
2. 클라이언트 사이드 라우팅 부분 적용
- Next.js의 Link 컴포넌트 활용
- 동적 라우팅이 필요한 부분만 선별적 적용
75. "Next.js를 사용하면서 가장 어려웠던 점은 무엇이었나요? 어떻게 해결하셨나요?"
서버 컴포넌트와 클라이언트 컴포넌트를 적절히 분리하는 것이 가장 어려웠습니다. 특히 상태 관리가 필요한 부분은 클라이언트 컴포넌트로, 정적인 부분은 서버 컴포넌트로 분리하는 작업이 까다로웠습니다. Next.js 공식 문서를 참고하고 'use client' 지시어를 활용해 컴포넌트를 명확히 구분하여 해결했습니다.
76. "상태 관리 라이브러리로 Redux와 Zustand를 사용해보셨는데, 둘의 차이점은 무엇인가요? 각각 어떤 상황에서 사용하시나요?"
Redux는 규모가 크고 복잡한 상태 관리에 적합하며, action, reducer 등의 보일러플레이트 코드가 필요합니다. Zustand는 더 간단한 API를 제공하고 설정이 쉬워 작은 규모의 프로젝트에 적합했습니다. 저는 전역적으로 관리해야 할 상태가 많은 경우 Redux를, 간단한 전역 상태 관리가 필요한 경우 Zustand를 사용했습니다.
77. 사용자 경험(UX)를 향상시키기 위한 방법에는 어떤 방법들이 있나요?
1. 성능 최적화 : 레이지 로딩 구현으로 초기 로딩 시간 단축, 이미지 최적화 (webp 포맷 사용, 적절한 크기 조정), 컴포넌트 코드 스플리팅, 불필요한 리렌더링 방지를 위한 메모이제이션 활용
2. 반응형 인터랙션 구현: 로딩 상태를 위한 스켈레톤 UI 또는 로딩 인디케이터 구현, 부드러운 애니메이션과 전환 효과 적용, 디바운싱/쓰로틀링을 통한 성능 최적화
3. 폼 처리 최적화 : 실시간 유효성 검사 구현, 적절한 에러 메시지 표시
78. 프록시 서버란?
프록시 서버는 클라이언트와 서버 사이에 위치한 중간 서버입니다, 클라이언트의 요청을 대신 받아서 실제 서버에 전달하는 중계 역할을 수행하며 주로 보안, 캐싱, CORS 우회 등의 목적으로 사용됩니다
CORS 우회 원리
1. CORS의 기본 동작
클라이언트(localhost:3000) → API 서버(api.example.com) ⤷ CORS 에러 발생 (출처가 다름)
2. 프록시를 통한 우회 동작
⤷ 같은 출처라서 CORS 에러 없음 ⤷ 서버 간 통신은 CORS 제약 없음
'면접준비' 카테고리의 다른 글
| 프론트엔드 면접 준비 : REST API 란? (0) | 2024.05.07 |
|---|---|
| 프론트엔드 면접 준비 : 클로저(Closure)란? (0) | 2024.05.01 |
| 프론트엔드 면접 준비 : 호이스팅(Hoisting) (0) | 2024.04.25 |
| 프론트엔드 면접 준비 : 웹 브라우저에 URL을 입력하면 어떤 일이 생기는가? (0) | 2024.04.17 |
| 프론트엔드 면접 준비 : 웹 브라우저란? (0) | 2024.04.15 |